Model Deployment & Serving
Deploy machine learning models securely on-premise, in the cloud, or at the edge. We build containerized serving environments using Docker, Kubernetes, gRPC, and optimized TensorRT to deliver predictions with ultra-low latency.
Live service view
Architecture pulse
Docker-packaged deployment ensures identical runs across any environment.
Deploy models as REST/gRPC APIs with optimized batching and rate limiting.
Edge deployment on mobile and IoT devices using ONNX and WebAssembly.
How We Work Step-by-Step
Our systematic approach guarantees modular integration, safety validation, and seamless deployment scaling.
Discovery & Planning
Understanding your business workflow, evaluating model artifacts, and determining baseline latency and throughput targets.
Custom Development
Building scalable AI & SaaS architecture, wrapping models in Docker, optimizing runtime engines (ONNX, TensorRT), and structuring gRPC/REST APIs.
Deployment & Scale
Launching and maintaining the servers, configuring auto-scaling node pools on Kubernetes (AWS/Azure), and applying GitOps continuous deployment.
Monitor & Optimize
Active logging of model input/output distributions, detecting drift, and automating feedback loops for continuous improvement.
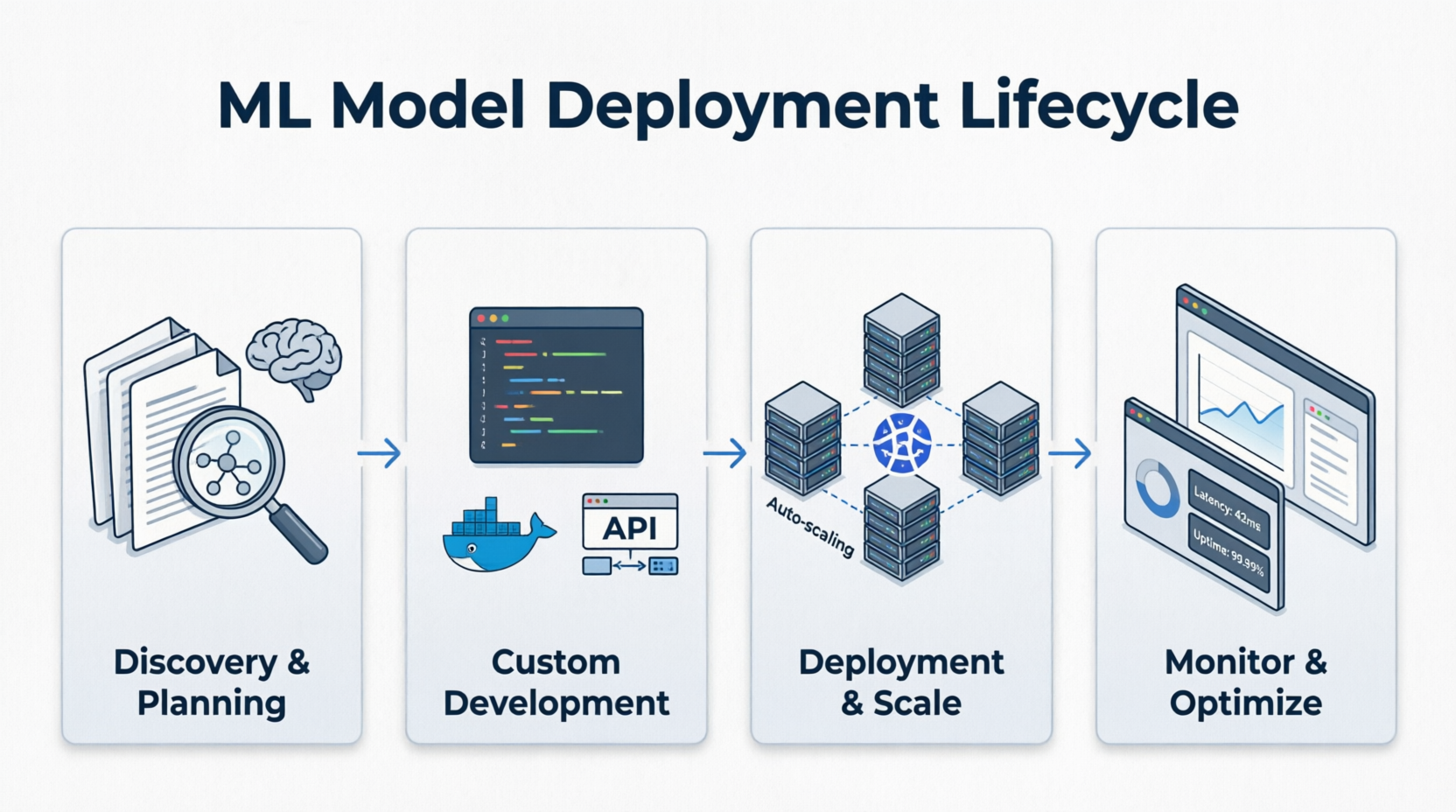
This flow shows the model moving from planning into API packaging, scaled deployment, and live monitoring.
Continue to monitoringModel serving topology
Client app requests move through the API gateway into Triton inference, backed by a model registry and production latency targets.
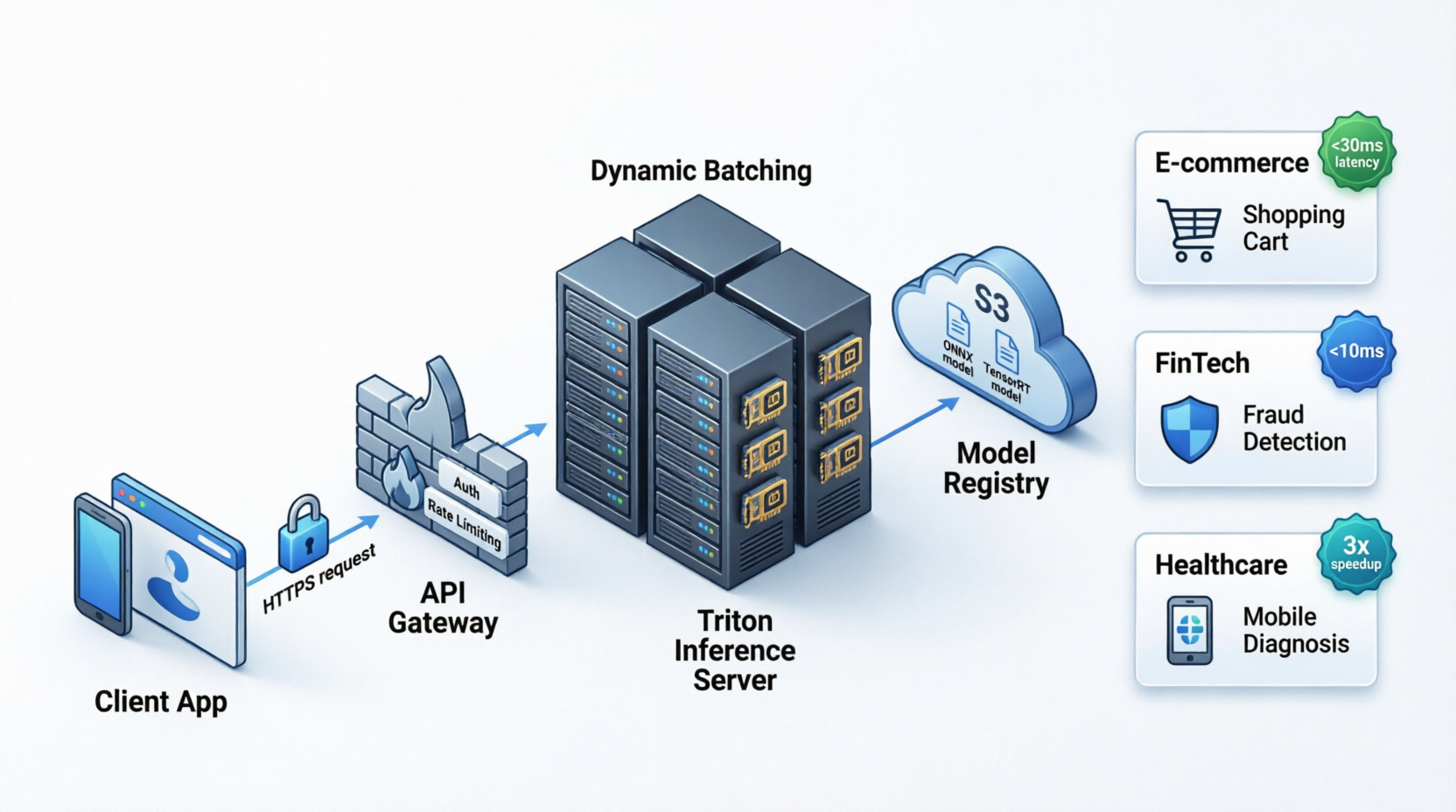
API Serving & Edge Pipeline
We leverage cloud-native tools to design isolated microservices. Below is the data-flow topology representing real-time traffic orchestration.
Key Features
- Secure containerized isolation
- Auto-scaling on load spikes
- Full state logging and tracing
Client App
REST / gRPC Request
API Gateway
Rate Limiting & Auth
Triton Server
Dynamic Batching & Inference
Model Registry
S3 Bucket / ONNX / TensorRT
Real-World Deployments
Industry Case Studies & Integration metrics
| Industry | Deployment Type | Infrastructure | Result Impact |
|---|---|---|---|
| E-Commerce | Recommender Systems | AWS ECS + Triton + Redis | <30ms Latency |
| FinTech | Fraud Detection | Kubernetes + gRPC + ONNX | <10ms Inference |
| Healthcare | Mobile-Edge Diagnosis | iOS/Android + CoreML/TFLite | 3x speedup local |